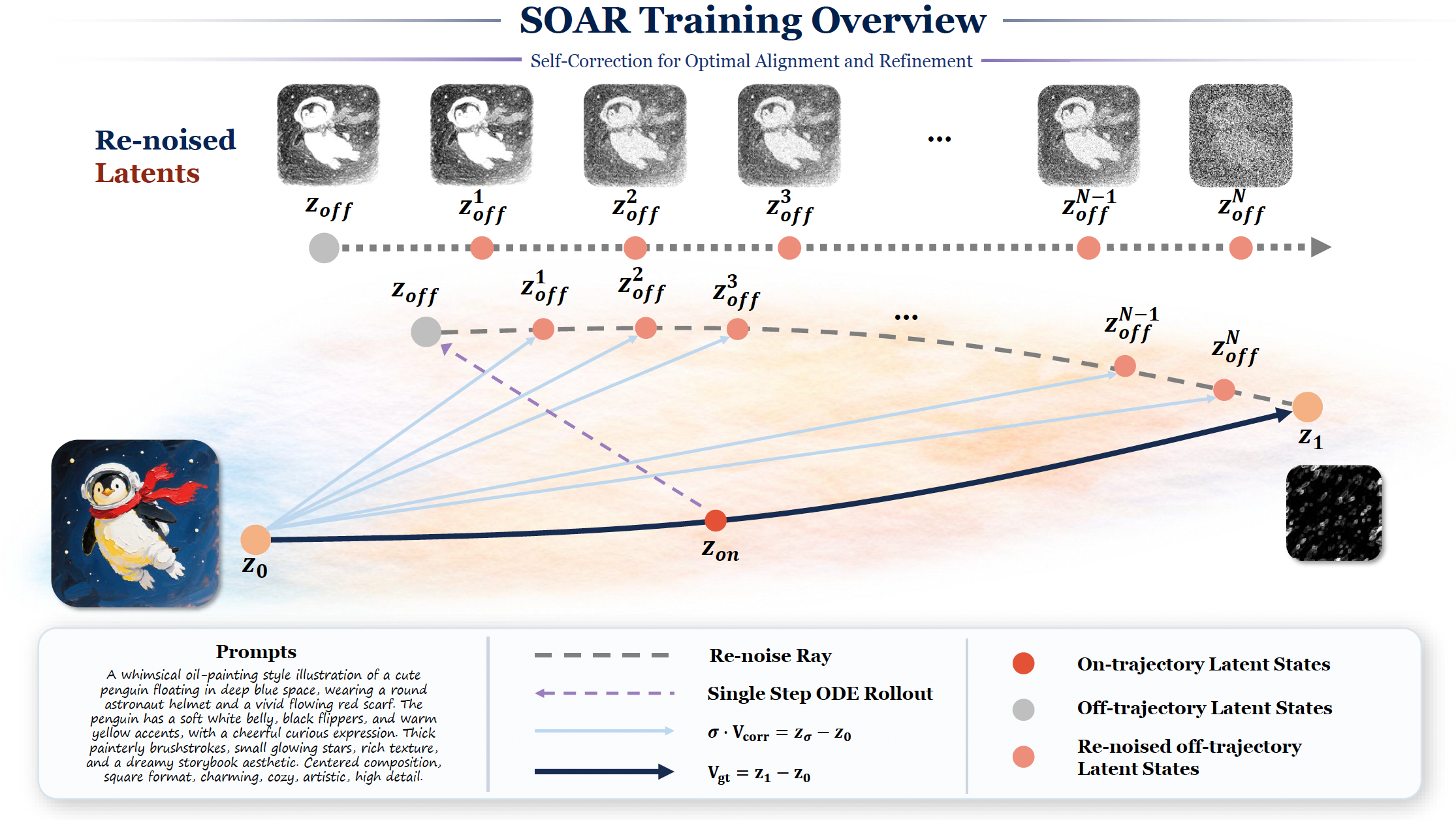
We propose HY-SOAR: a scalable, reward-free post-training framework for trajectory-level self-correction in rectified-flow diffusion models, which targets exposure bias in the denoising trajectory by sampling on-trajectory noisy states, performing one stop-gradient CFG rollout with the current model, re-noising the resulting off-trajectory states toward the same noise endpoint, and supervising the denoiser with analytical correction targets to provide an on-policy, dense, and reward-free training signal.
SOAR provides a principled, reward-free approach to trajectory-level correction
Directly addresses the mismatch between ground-truth training states and model-induced inference states — the root cause of compounding denoising failures.
Off-trajectory states are produced by the current model's own rollout, so the training distribution co-evolves with the model instead of staying fixed.
Requires no reward model, preference labels, or negative samples. Provides per-timestep correction supervision and avoids terminal-reward credit assignment.
Re-noising uses the same noise endpoint as the base flow-matching pair, keeping auxiliary states near the original transport ray.
The SOAR loss extends the standard flow-matching objective and can replace SFT as a stronger first stage, remaining compatible with later RL alignment.
Visual comparisons of SOAR vs Flow-GRPO vs SFT across different reward objectives
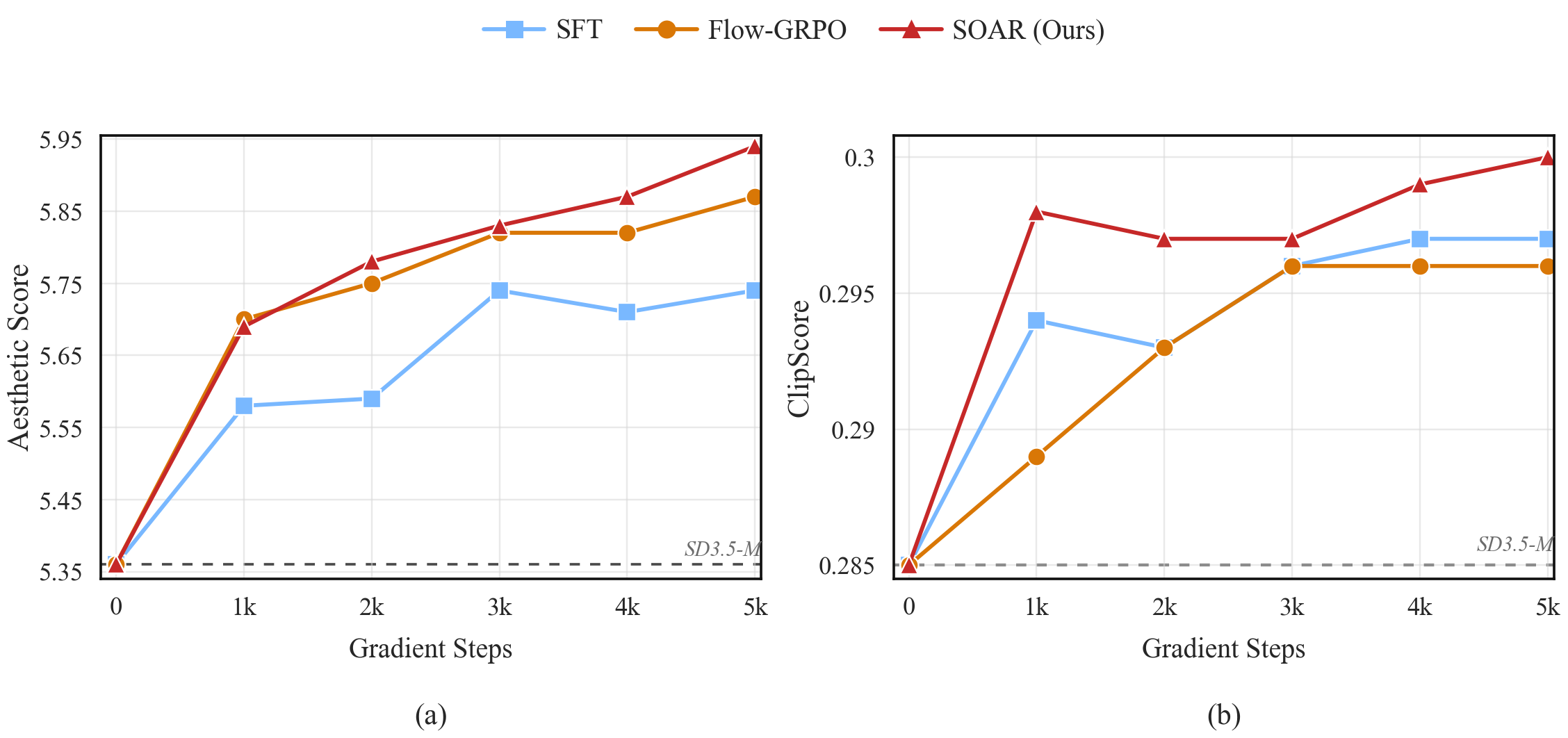
Comparison across training steps, optimizing for aesthetic quality on diverse prompts — historical scenes, fantasy art, and character portraits.

Comparison on design and poster generation prompts, optimizing for text-image alignment. SOAR demonstrates stronger text rendering and compositional fidelity.

SOAR results on web UI and graphic design generation, showing accurate layout, typography, and visual hierarchy.

Main results on DrawBench and GenEval/OCR test sets
Following Flow-GRPO, we evaluate image quality and human preference scores on DrawBench prompts, and task-specific metrics on the GenEval/OCR test sets. All models are trained at 512×512 with cfg=4.5.
| Model | #Iter | GenEval | OCR | PickScore | ClipScore | HPSv2.1 | Aesthetic | ImgRwd |
|---|---|---|---|---|---|---|---|---|
| SD-XL (1024²) | – | 0.55 | 0.14 | 22.42 | 0.287 | 0.280 | 5.60 | 0.76 |
| SD3.5-L (1024²) | – | 0.71 | 0.68 | 22.91 | 0.289 | 0.288 | 5.50 | 0.96 |
| FLUX.1-Dev | – | 0.66 | 0.59 | 22.84 | 0.295 | 0.274 | 5.71 | 0.96 |
| SD3.5-M | – | 0.63 | 0.59 | 22.34 | 0.285 | 0.279 | 5.36 | 0.85 |
| + SFT | 10k | 0.70 | 0.64 | 22.71 | 0.295 | 0.284 | 5.35 | 1.04 |
| + SOAR (Ours) | 10k | 0.78 | 0.67 | 22.86 | 0.295 | 0.289 | 5.46 | 1.09 |
SOAR raises SD3.5-Medium's GenEval score from 0.70 to 0.78 (+11% relative) and OCR accuracy from 0.64 to 0.67, while simultaneously improving every DrawBench quality and preference metric — all without any reward model during training.
In head-to-head comparisons on DrawBench Aesthetic Score and ClipScore, SOAR's final scores not only surpass SFT but also outperform Flow-GRPO, which explicitly uses these metrics as its reward signal (Aesthetic: 5.94 vs. SFT 5.74 / Flow-GRPO 5.87; ClipScore: 0.300 vs. SFT 0.297 / Flow-GRPO 0.296).
If you find SOAR useful in your research, please cite our work